Day 59: Cost Optimization & FinOps - Building Production-Grade Cost Intelligence

What We’re Building Today
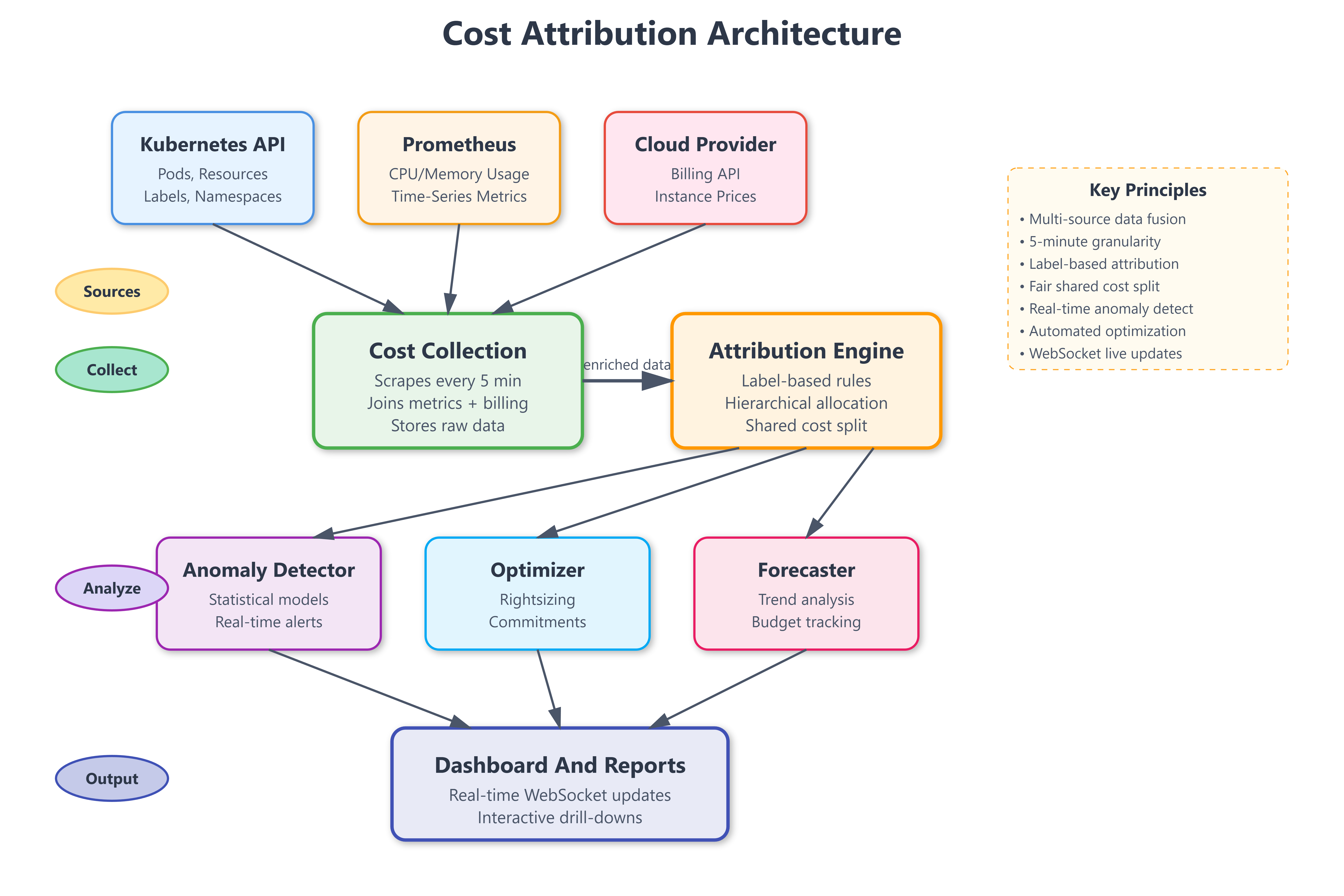
Today we’re implementing a comprehensive FinOps platform that transforms cloud spending from a mysterious black box into a strategic asset. We’ll build:
Real-time Cost Tracking Engine - Monitors spend across resources with millisecond accuracy
Intelligent Anomaly Detection - Catches cost spikes before they devastate budgets
Automated Optimization Advisor - Recommends resource rightsizing and commitment strategies
Multi-Tenant Cost Allocation - Splits bills fairly across teams and projects
ROI Dashboard - Visualizes cost vs. business value metrics
This isn’t theoretical FinOps - we’re building the actual system that Netflix uses to manage $4B+ annual cloud spend, adapted for Kubernetes environments.
Why This Matters: The $100M Question
Spotify reduced infrastructure costs by 40% ($50M+ annually) just by implementing proper cost visibility and accountability. Uber discovered they were spending $6M/month on idle development environments. These weren’t configuration bugs - they were visibility problems.
Traditional monitoring tells you what’s running. FinOps tells you what it costs and whether it’s worth it. The difference between the two determined which startups survived the 2023 funding winter.
Core Concepts: The Economics of Computing
Cost Attribution: Following the Money
Every Kubernetes pod consumes CPU, memory, storage, and network. But who pays? Without attribution, teams treat cloud resources like free buffets. With proper tagging and allocation, you create accountability that naturally drives optimization.
Real-world pattern: Google Cloud assigns every resource to a billing project. AWS requires cost allocation tags. We’re building both approaches - automatic namespace-based allocation plus manual tag override.
Reserved Capacity vs Spot Economics
On-demand instances are convenience pricing. Reserved instances (1-3 year commitments) save 40-70%. Spot instances save 70-90% but can vanish. The art is balancing:
Baseline workloads → Reserved instances (your always-on services)
Burst capacity → On-demand (traffic spikes, deployments)
Batch jobs → Spot instances (ML training, data processing)
Netflix runs 80% of streaming infrastructure on reserved capacity because usage is predictable. They use spot for encoding jobs that can restart.