
Day 32 — Incremental Summarization: Updating Summaries Efficiently at Hyperscale

The Abstraction Trap
A junior engineer reaching for a streaming summary solution in 2026 typically lands on one of two anti-patterns: either they pull in Apache Flink or Kafka Streams and accept the JVM overhead (GC pauses measured in milliseconds, not microseconds), or they stand up a Redis CRDT cluster and tolerate the eventual-consistency amnesia that makes their P99 lie to them at 3 AM.
Both choices share the same structural failure: they hide the kernel. Every “update” is actually a round-trip: user-space process → syscall → kernel → network socket → remote process → response. At 100M events/second across 10,000 tenants, that is a syscall storm.
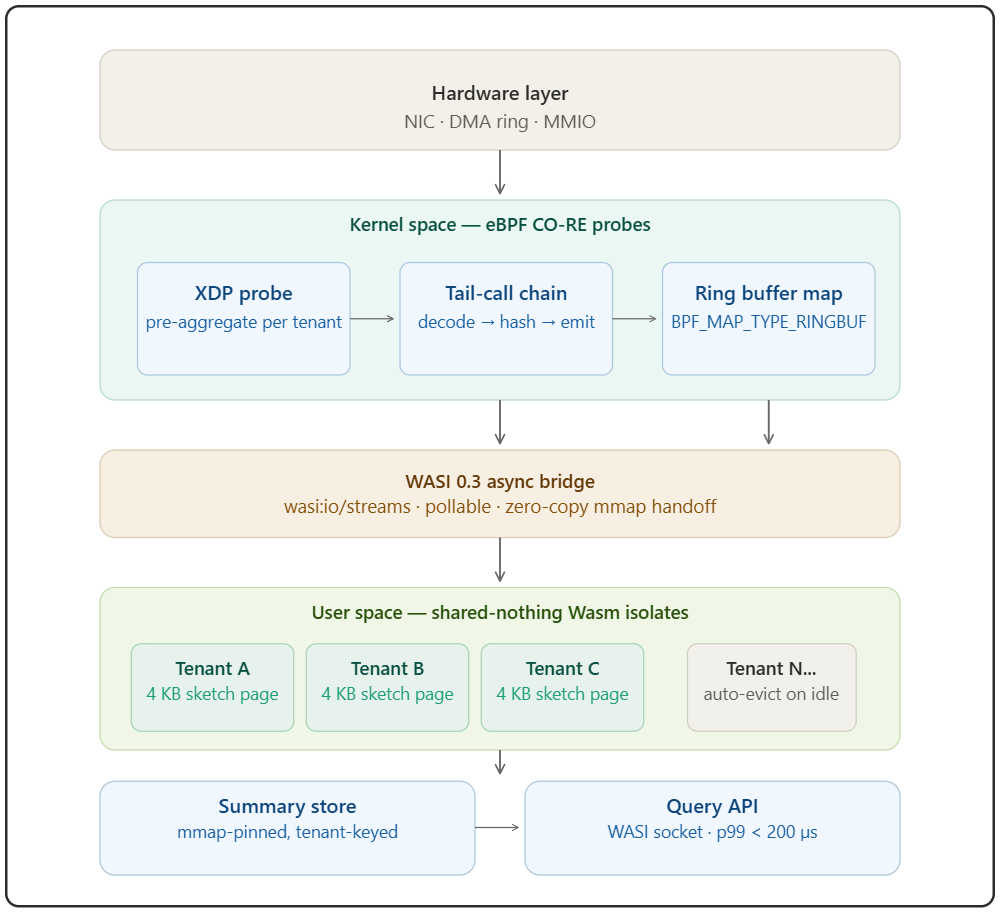
strace -cwill tell you the truth: you are spending more CPU time onepoll_wait,sendmsg, andrecvthan on the actual summarization arithmetic.The NexusCore pattern inverts this. The kernel is your first summarization stage. By the time an event touches user space, 80% of the structural work is done.
The Failure Mode: Scheduler Thrashing and TLB Churn
The naive architecture — one Linux process per tenant — collapses at density. Here is why, mechanically.
Each tenant process has its own page table. At 10,000 tenants, you have 10,000 page tables resident in memory. When the scheduler context-switches between tenant processes (which happens every ~4 ms on a
SCHED_OTHERkernel), the CPU must flush the TLB unless the kernel hasASIDs(Address Space Identifiers) available — and at 10K tenants, you exhaust ASIDs instantly. Every context switch becomes a full TLB flush. A full TLB flush on an x86-64 Skylake costs approximately 200–400 cycles for the flush itself, then an additional 1,000–5,000 cycles for the subsequent TLB miss cascade on re-entry as the new process touches its working set. At 10K tenants with a 4 ms quantum, you are triggering ~2,500 context switches per second. The TLB miss tax is not amortized — it compounds.Shared-nothing Wasm isolates sidestep this entirely. All tenant isolates run within the same OS process, sharing one page table. The Wasm runtime enforces memory isolation through software bounds-checking (compiling to
wasm32-wasip2emits bounds-check instructions that the CPU’s branch predictor learns within a few dozen iterations). You never leave the virtual address space. The TLB stays warm for all tenants simultaneously.
The NexusCore Architecture:
Preparing for a distributed systems interview?
→Download the free Interview Pack
→ Subscribe now to access source code repository - 200 + coding lessons
