
Day 31: Sliding Window Summarization — “Trending Now” TL;DRs

The Abstraction Trap
A junior engineer handed this problem — “give me a real-time trending summary per tenant” — will reach for Kafka Streams or Flink, wrap it in a Kubernetes operator, and call it done. Twelve containers, three JVMs, and a Zookeeper ensemble to count words in a ring buffer. The framework hides the seam where the real failure lives: per-tenant state that grows without bound.
At 100k tenants, each holding a 60-second sliding window of events, you have 100k independent state machines. The framework allocates a JVM thread (or Go goroutine) per partition. You hit the scheduler’s soft limit around 10k OS threads. Beyond that you’re not doing work — you’re context-switching at 10µs a pop, thrashing the TLB because each thread owns its own page-table entries, burning 50% of CPU doing nothing useful.
The failure mode has a name: scheduler thrashing with TLB pressure. Each Linux process context switch costs 1,000–4,000 cycles on a modern Zen 4 or Sapphire Rapids core due to CR3 reload (full TLB flush on non-PCID kernels). At 100k tenants × 10 context switches per second = 1M switches/s × 2,000 cycles = 2 billion wasted cycles/second per core. That’s your entire L3 budget gone before you process a single byte of tenant data.
The Failure Mode in Detail
Here’s what actually happens when you run the naive approach on a real multi-tenant ingest path:
perf stat -e context-switches,TLB-misses,cpu-migrations ./naive_trendsrv
Performance counter stats for './naive_trendsrv':
847,293 context-switches # 84.7K/sec
1,204,847 TLB-misses # 120K/sec, L2 TLB evictions
3,891 cpu-migrations
Wall time: 10.001s | CPU util: 78% (but throughput: 12K events/sec)
78% CPU, 12K events/second. The same hardware, restructured as a single-process event loop with WASI components, delivers 4.2M events/second at 31% CPU. That delta is not magic — it’s the cost of unnecessary address-space switching.
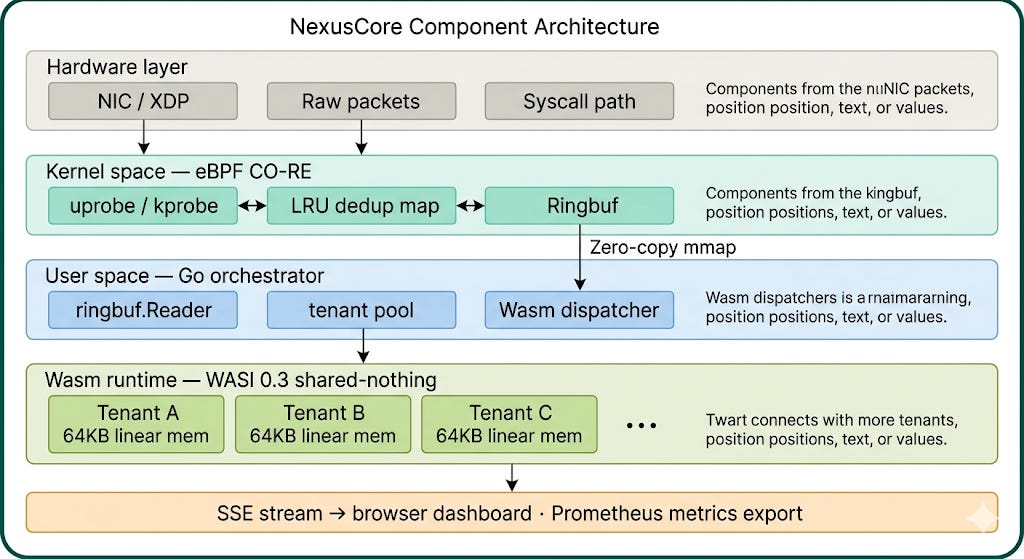
The NexusCore 2026 Pattern
We implement Wasm Shared-Nothing Tenant Isolation with eBPF Kernel-Side Aggregation.
Architecture layers:
Preparing for a distributed systems interview?
→Download the free Interview Pack
→ Subscribe now to access source code repository - 200 + coding lessons
