Day 27: Structured Intelligence — Forcing LLM Output into JSON

The Problem Is Not the LLM. It Is Your Architecture.
Every junior engineer building LLM-backed services eventually writes the same garbage:
response = openai.chat.completions.create(...)
text = response.choices[0].message.content
data = json.loads(text) # pray
When
json.loadsthrows, they add a retry. When the retry fails, they add regex. When regex fails, they hire a prompt engineer. This entire tower of workarounds exists because they outsourced a deterministic problem — schema enforcement — to a probabilistic system — the language model.The LLM is not your JSON serializer. It is a token sampler. The fact that it usually emits valid JSON means nothing at 100,000 concurrent tenants. At that density, “usually” is thousands of failures per second, each burning a retry budget, each introducing head-of-line latency, each corrupting the P99 that your SLA depends on.
The correct frame: JSON schema validation is a parsing problem. Parsing problems have O(n) deterministic solutions. Build one.
The Abstraction Trap: What “Structured Output” SDKs Hide
In 2025, every LLM SDK shipped a
response_format={"type": "json_object"}knob. Teams celebrated. The failure rate dropped. Nobody asked why it dropped — and that ignorance will cost you.What those SDKs actually do is inject a logit bias at the sampling layer. At each decoding step, they mask out token IDs whose continuation would violate JSON grammar at that position. This is constrained decoding via a grammar automaton running inside the inference engine. It works beautifully — until it doesn’t.
The failure modes that get hidden:
Schema drift.
json_objectguarantees syntactic JSON. It does not guarantee your schema.{"status": null, "items": false}is valid JSON. It will break your downstream code. The SDK does not know your schema unless you also pass a JSON Schema and the provider actually implements it — which, in 2026, remains provider-dependent and underspecified.Streaming blindspot. Constrained decoding enforces validity on the complete output. When you are streaming token-by-token for latency, you receive a stream of tokens that are grammatically valid in isolation but not schema-valid until the final brace closes. If your consumer tries to parse partial output, you get parse errors mid-stream.
Black-box observability. When the SDK’s logit mask fires, you have no telemetry. You cannot tell which tokens were masked, which grammar states were visited, or whether the constraint is slowing generation. In a multi-tenant system, you cannot attribute this latency per tenant. The kernel scheduler does not know about your JSON automaton.
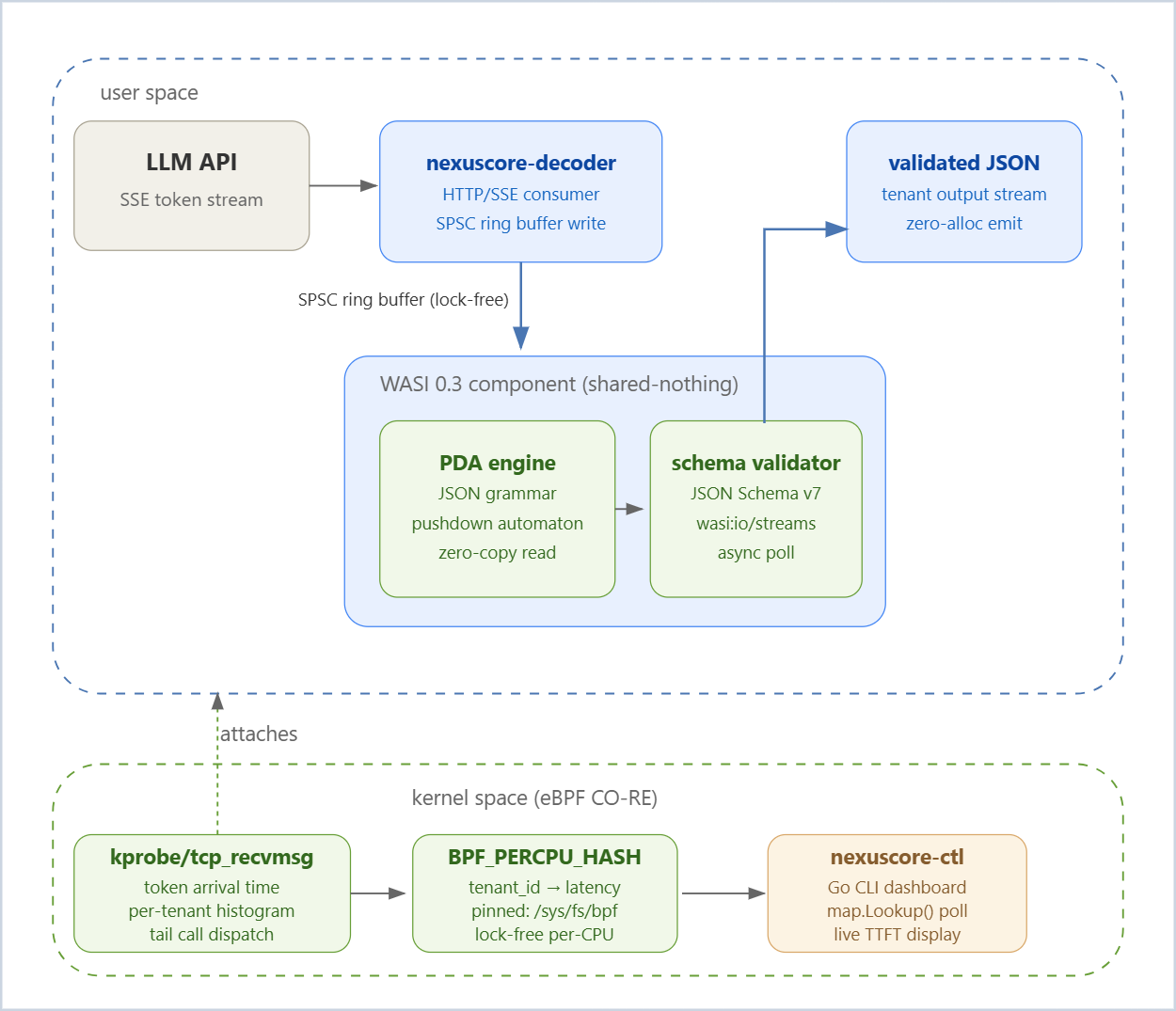
The NexusCore approach: run grammar enforcement in your infrastructure, not in the provider. You own the pushdown automaton. You own the ring buffer it reads from. You own the eBPF probe that measures when each token byte crossed the socket boundary. The LLM is just a token source.
The Failure Mode: Heap Fragmentation and Scheduler Thrashing
The naive implementation spawns a thread per tenant, allocates a
Stringper token, appends to aVec<u8>, then parses the whole buffer withserde_jsonat stream end.At 100k tenants, this produces:
TLB pressure. Each tenant’s buffer lives at a random heap address. The token-processing hot loop accesses memory at random virtual pages. The TLB — 1,536 entries on a modern x86 core — thrashes. Every TLB miss costs 50–200 cycles for a page table walk. At 10M tokens/sec, even a 1% miss rate is 50M wasted cycles per second per core.
Heap fragmentation.
String::push_strtriggers reallocation at 1.5× growth. With 100k concurrent tenants each at different allocation stages, the allocator’s free lists fragment.jemalloc‘s per-thread caches fill. Cross-thread frees cause lock contention in the size-class bins.Scheduler thrashing. 100k threads on a 32-core machine means the Linux CFS scheduler maintains 100k
sched_entitystructs. The wakeup path —try_to_wake_up()→ load balancing → migrating tasks across CPUs — runs thousands of times per second. Cache lines containing task metadata ping-pong between L3 slices. The scheduler itself becomes a bottleneck, consuming 5–10% of CPU on scheduling overhead alone.The fix: eliminate threads per tenant. Eliminate per-token allocation. Use a fixed-size, cache-line-aligned ring buffer per tenant instance, read by a WASI component running on a small pool of async workers.
The NexusCore Architecture: Deterministic JSON at the Platform Layer