
Day 25: Real-Time Classification — Tagging the Redpanda Stream

The Problem in Plain Terms
You have a Redpanda broker ingesting eight hundred thousand events per second from fifty thousand tenants. Each event needs a semantic tag —
fraud-signal,churn-risk,high-value,anomaly— before it lands in the downstream topic. Latency budget: under 200 microseconds end-to-end, including the tag write. Miss that budget and you break real-time guarantees for every system downstream: the alerting engine, the billing auditor, the ML feature store.The naive path is to stand up a Kafka consumer group in Go or Python, load a rule engine per process, and horizontally scale with Kubernetes. Let’s discuss why that fails before we discuss what works.
The Abstraction Trap
A junior engineer reaches for Apache Flink or Spark Structured Streaming. Both are defensible choices at moderate scale. At hyperscale multi-tenancy they become the problem.
Flink gives you a
KeyedProcessFunction. You key the stream bytenant_id. At 50,000 tenants, Flink maintains 50,000 in-flight state backends, each with its own RocksDB compaction thread, each fighting the JVM garbage collector for CPU time. Your 200 µs budget evaporates the moment a minor GC pause hits a tenant’s state shard. The framework hides this: you see a backpressure metric tick up, you see checkpoint duration creep from 400 ms to 4 seconds, and you never see the root cause because it’s buried three layers below the abstraction.The hidden failure mode is scheduler thrashing. With one Linux process per Flink task slot, the kernel’s CFS scheduler interleaves 50,000 runnable threads across 64 cores. Each context switch costs between 1,000 and 5,000 CPU cycles in direct overhead, plus another 10,000–100,000 cycles in indirect TLB shootdown and cache invalidation. At 50,000 concurrent classifiers you are spending more CPU on scheduling overhead than on actual classification work. You cannot see this from the framework’s dashboard — it looks like high CPU utilization. It is high CPU utilization doing nothing useful.
The Scale Pain: Memory Density and TLB Pressure
The deeper problem is physical memory layout. A JVM-based classifier per tenant needs a minimum of 64 MB of heap (post-JIT, with minimal state). 50,000 tenants × 64 MB = 3.2 TB of RAM. That is not a deployment you run. You run a much smaller number of shared JVM processes, which means shared heap, which means tenants interfere with each other’s GC pressure. A single high-volume tenant triggers a full GC and everyone’s latency spikes.
Even with native code (C, Go, Rust binaries) the process-per-tenant model fails at lower numbers than people expect. Each process has its own page table. At 10,000 tenant processes, the kernel’s page table memory alone exceeds 40 GB. More importantly, the CPU’s TLB (Translation Lookaside Buffer) — which caches virtual-to-physical page mappings — has between 64 and 4,096 entries depending on the architecture. With 10,000 processes, every context switch is a near-total TLB flush. Every memory access following a context switch becomes a page walk: 4 memory accesses to traverse the x86-64 4-level page table, at 60–200 ns each. A 64-byte cache line read that should cost 4 ns now costs 800 ns.
This is why Wasm shared-nothing components at the runtime level, not the OS process level, are the correct 2026 architecture for multi-tenant classification.
The NexusCore Architecture
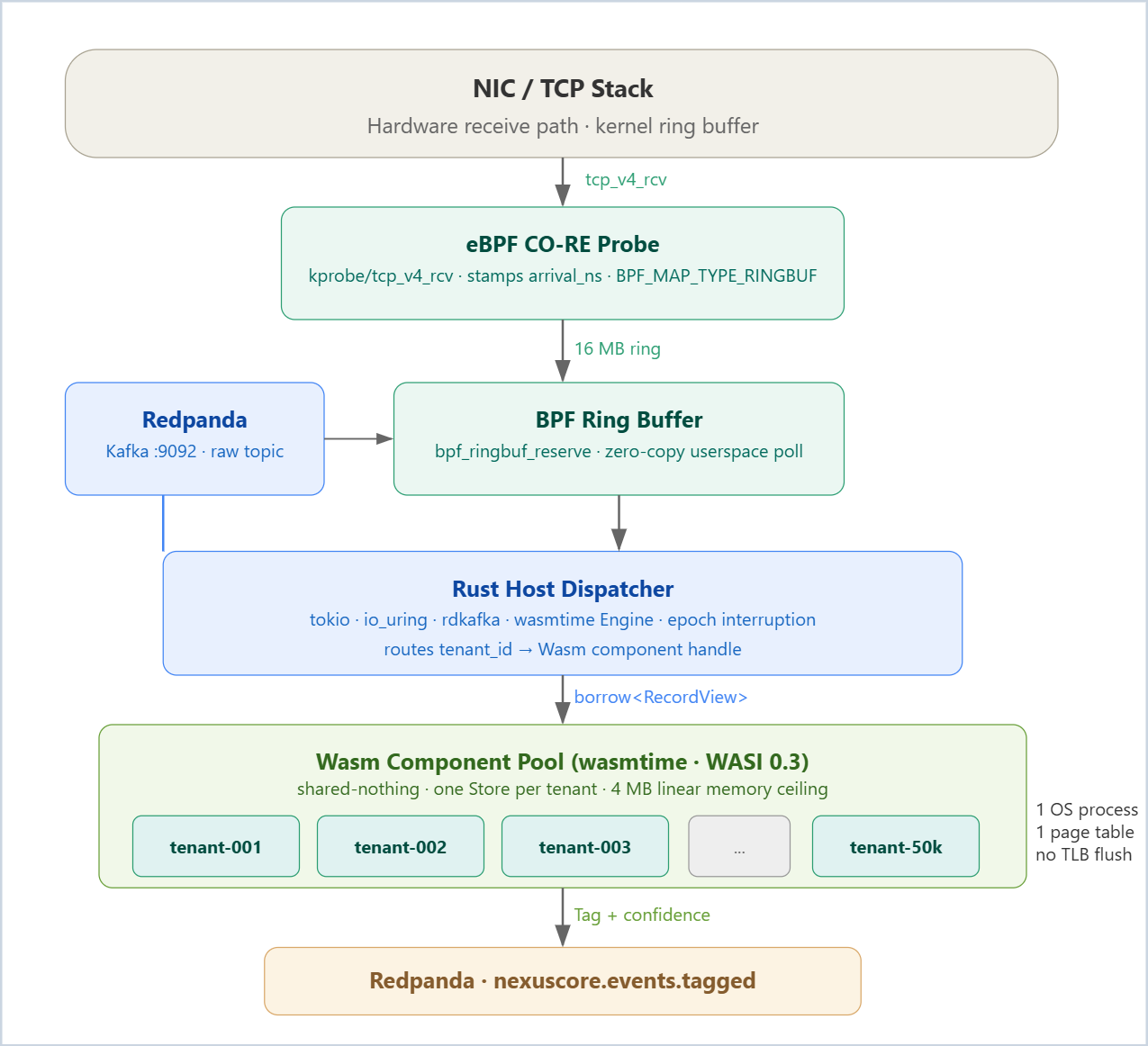
Three structural decisions drive this architecture.
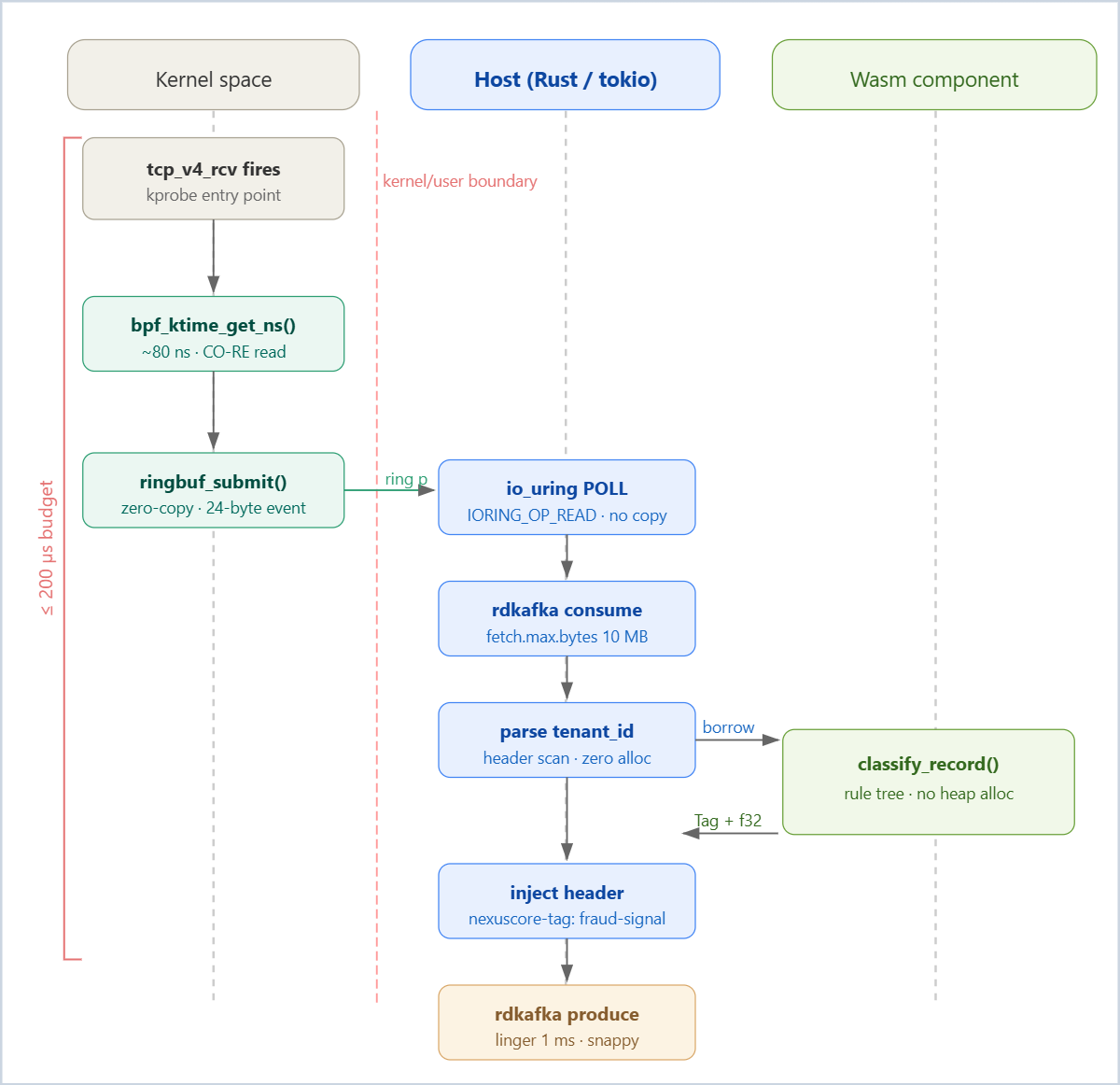
Decision 1: eBPF timestamps at the socket layer. The moment a Kafka record’s TCP segment hits the kernel receive path, an eBPF program stamps a high-resolution kernel timestamp (bpf_ktime_get_ns()) into a BPF ring buffer. This costs approximately 80 ns in kernel time and adds no allocations. The host process reads this timestamp alongside the record, giving it an accurate ingestion latency metric that is immune to userspace scheduler jitter.
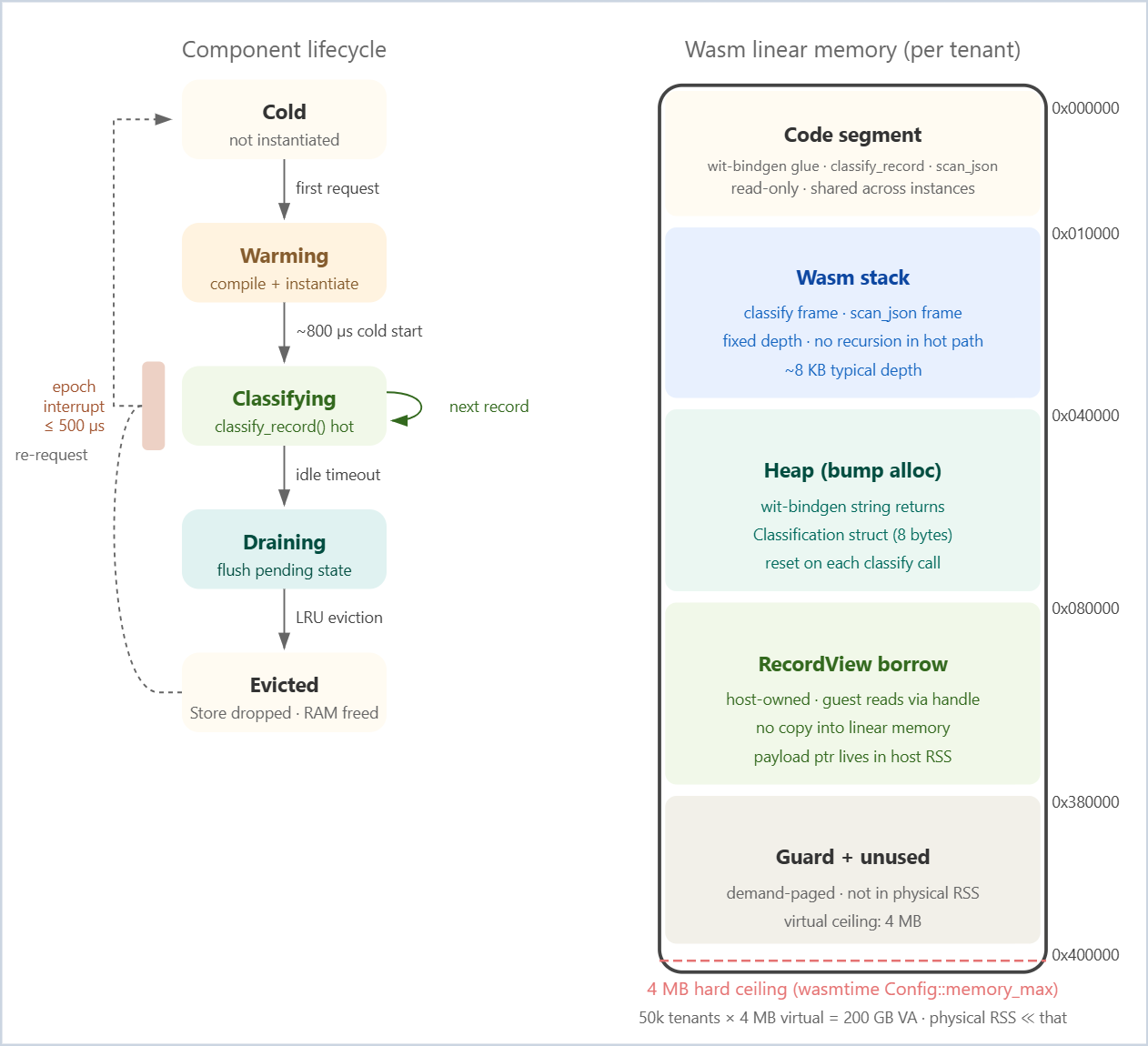
Decision 2: WASI 0.3 components for tenant isolation. Each tenant’s classification policy is compiled to a Wasm component conforming to a WIT interface. The wasmtime runtime instantiates one component per tenant and pools them. Critically, all 50,000 component instances share a single OS process and a single page table. The TLB sees one address space. Context switching between tenant classifiers is a wasmtime stack swap, not an OS context switch — it costs approximately 200 ns versus 5,000 ns. At 50,000 tenants the savings are 240 ms of CPU per second compared to the process-per-tenant model. Memory density: 4 MB linear memory per component × 50,000 = 200 GB, but wasmtime uses demand-paged virtual memory, so physical RSS is proportional to the working set actually accessed, not the address space ceiling.
Decision 3: Zero-copy record passing. The Redpanda Kafka protocol uses a length-prefixed binary format. When the host process reads a record from the BPF ring buffer consumer (via io_uring IORING_OP_READ), it does not copy the payload into a new heap allocation. It passes a pointer and length to the Wasm component as a RecordView — a WIT resource that wraps a host-managed memory region. The Wasm component reads record fields through this resource handle. No allocation inside linear memory for the record payload itself. The classifier returns a Tag (an enum plus a score f32), which is eight bytes on the wire.
Implementation Deep Dive
GitHub Link :
https://github.com/sysdr/nexus-core-devops-engineering-p/tree/main/lesson25/nexuscore-day25
The WIT Interface
// nexuscore-classifier.wit
package nexuscore:classifier@0.1.0;
interface classify {
resource record-view {
tenant-id: func() -> string;
payload: func() -> list<u8>;
timestamp-ns: func() -> u64;
}
enum tag {
fraud-signal,
churn-risk,
high-value,
anomaly,
pass,
}
record classification {
tag: tag,
confidence: f32,
latency-ns: u64,
}
classify-record: func(rec: borrow<record-view>) -> classification;
}
world classifier-component {
export classify;
}
The borrow<record-view> annotation is critical — it is WASI 0.3 component model syntax for “the host owns this resource; the Wasm guest may read it but not drop it.” This prevents the guest from freeing host-managed memory. Without borrow, a malicious or buggy tenant component could call the destructor on a record buffer shared across other tenants’ classification pipelines.
eBPF Probe: Kernel Timestamp Injection
// nexuscore_ts.bpf.c — CO-RE, compiled with clang + bpftool
#include <vmlinux.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
struct event {
__u64 arrival_ns;
__u32 saddr;
__u16 sport;
__u16 dport;
};
struct {
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 1 << 24); // 16 MB ring
} events SEC(".maps");
SEC("kprobe/tcp_v4_rcv")
int BPF_KPROBE(trace_tcp_rcv, struct sk_buff *skb)
{
struct event *e = bpf_ringbuf_reserve(&events, sizeof(*e), 0);
if (!e) return 0;
e->arrival_ns = bpf_ktime_get_ns();
// CO-RE: safe field access without kernel header coupling
struct iphdr *ip = (struct iphdr *)(BPF_CORE_READ(skb, head) +
BPF_CORE_READ(skb, network_header));
e->saddr = BPF_CORE_READ(ip, saddr);
struct tcphdr *tcp = (struct tcphdr *)((void *)ip + (BPF_CORE_READ(ip, ihl) << 2));
e->dport = bpf_ntohs(BPF_CORE_READ(tcp, dest));
e->sport = bpf_ntohs(BPF_CORE_READ(tcp, source));
bpf_ringbuf_submit(e, 0);
return 0;
}
char LICENSE[] SEC("license") = "GPL";
Note the use of BPF_CORE_READ throughout. This is eBPF CO-RE (Compile Once – Run Everywhere): the BTF type information embedded in the kernel ELF allows the BPF loader to rewrite field offsets at load time, making the probe portable across kernel versions without recompilation. If you use direct pointer arithmetic on skb->head without CO-RE and the kernel struct layout shifts (which it does across versions), your probe silently reads garbage.
Rust Host: Ring Buffer Consumer and Wasm Dispatch
The host uses libbpf-rs to poll the ring buffer and wasmtime with the component model to dispatch to tenant classifiers:
// src/dispatcher.rs
use libbpf_rs::RingBuffer;
use wasmtime::component::{Component, Linker, ResourceTable};
use wasmtime_wasi::WasiCtxBuilder;
pub struct Dispatcher {
engine: wasmtime::Engine,
components: HashMap<TenantId, wasmtime::component::Instance>,
rb: RingBuffer<'static>,
}
impl Dispatcher {
pub fn run(&mut self) {
loop {
// Poll BPF ring buffer — zero blocking, returns immediately
// if empty. io_uring drives the actual wakeup.
self.rb.poll(Duration::from_micros(50)).unwrap();
}
}
fn on_record(&mut self, event: &BpfEvent, kafka_record: &[u8]) {
let tenant_id = parse_tenant_header(kafka_record);
let instance = self.components.get(&tenant_id).unwrap();
// Pass record as a borrow — no copy into Wasm linear memory
let tag = instance
.exports(&mut self.store)
.instance("nexuscore:classifier/classify")
.unwrap()
.typed_func::<(RecordViewResource,), (Classification,)>("classify-record")
.unwrap()
.call(&mut self.store, (RecordViewResource::new(kafka_record, event.arrival_ns),))
.unwrap();
self.produce_tagged(kafka_record, tag, event.arrival_ns);
}
}
The RecordViewResource wraps a raw byte slice. It is registered in wasmtime’s ResourceTable and handed to the guest as an opaque handle — the guest never sees the host’s memory address, only an integer handle it uses to call back through the WIT interface methods.
Working Demo Link :
Production Readiness: Metrics That Matter
Metric Target Collection Point classify_latency_p99_us < 180 µs Wasm return → produce call bpf_ringbuf_drops_total 0 libbpf_rs stats callback wasm_cold_start_us < 800 µs Component instantiation timer tlb_shootdown_rate < 100/sec per core perf stat -e dTLB-load-misses kafka_produce_lag_ms < 5 ms rdkafka internal queue depth wasm_linear_memory_bytes < 4 MB per tenant wasmtime instance memory query
The bpf_ringbuf_drops_total counter is the most important early warning signal. A non-zero value means your ring buffer is filling faster than the userspace consumer drains it. The fix is almost never “make the ring bigger” — it is “fix the consumer loop.” Adding ring buffer capacity just delays the drop event while hiding the real problem.
For TLB shootdowns, perf stat -e dTLB-load-misses per-core should stay below 100/second on the dispatcher core. Above that, you are paying the page-walk tax. Investigate which Wasm component is accessing the most memory pages — a classifier loading a large decision tree model on every call is the typical culprit.
Step-by-Step Setup
Prerequisites
# Rust 1.80+ with WASI component target
rustup target add wasm32-wasip2
# wasm-tools for WIT binding generation
cargo install wasm-tools
# wasmtime CLI for local testing
cargo install wasmtime-cli
# bpftool for BPF CO-RE compilation
sudo apt install linux-tools-$(uname -r) clang libbpf-dev
# Redpanda (broker only — Docker)
docker run -d --name redpanda \
-p 9092:9092 -p 9644:9644 \
docker.redpanda.com/redpandadata/redpanda:latest \
redpanda start --overprovisioned --smp 1 --memory 1G
Verification
# Confirm BPF probe loads cleanly
sudo bpftool prog show | grep nexuscore_ts
# Check ring buffer is not dropping
sudo bpftool map show | grep events
# Look for: "entries" count growing, not wrapping
# Validate Wasm component WIT interface
wasm-tools component wit target/wasm32-wasip2/release/tenant_classifier.wasm
# Run the end-to-end classify latency benchmark
cargo run --bin bench -- --tenants 100 --rps 50000 --duration 60s
# Watch live metrics
cargo run --bin dashboard
Enjoying this free lesson?
Unlock the full version for deeper insights, advanced examples, and practical implementation guides.
Homework: Production-Level Challenge
Challenge: Adaptive Classifier Warm Pool with Eviction
The current architecture instantiates a Wasm component for each tenant at first request. At 50,000 tenants, cold starts on the long tail matter. Your homework:
Implement a warm pool of pre-instantiated Wasm components (pool size configurable, default 1,000) that are pre-loaded with the most recently active tenant policies.
Write an eviction policy based on a least-recently-used (LRU) + access-frequency composite score. Tenants with high access frequency but low recency should rank above tenants with low frequency but high recency.
Add a metric:
classifier_cache_miss_ratewith sub-1% target. Measure cold start cost vs warm start cost and confirm the pool size needed to achieve the target on a realistic tenant access distribution (hint: Zipf distribution with s=1.2 is a reasonable model for SaaS traffic).Make the pool size dynamically adjustable via a BPF map — the eBPF probe observes which tenants are active in real-time and pushes a frequency table to userspace without a syscall per event.