Day 19: Vector Quantization — Optimizing Indices for High-Density Storage

The Abstraction Trap
A junior engineer deploying a vector database for 10,000 tenants will reach for FAISS wrapped in a gRPC service, containerised per tenant. Each container runs OpenBLAS flat-scan over float32 vectors. By the time load hits 1,000 QPS per tenant, you are observing three simultaneous failure cascades:
Memory bandwidth saturation. At 1536-dimensional float32 embeddings, each vector is 6,144 bytes. A flat scan over 1 million vectors per tenant reads 5.8 GiB from DRAM per query. At 1,000 QPS, that’s 5.8 TB/s of memory bandwidth demanded — but DDR5-6400 dual-channel provides roughly 102 GB/s. You are off by a factor of 57 before a single computation begins.
TLB thrashing. The Linux TLB on x86_64 has 1,536 L2 entries. 10,000 FAISS processes means constant TLB shootdowns. Every miss costs 200–300 ns of page-table walk — linear in the number of tenants sharing the same NUMA node.
Scheduler context-switch overhead. OpenBLAS queries spawn BLAS threads. At 10K tenants × 8 BLAS threads = 80,000 live threads. The Linux CFS scheduler burns its entire quantum budget shuffling them. Effective CPU utilisation for actual computation drops below 15%.
None of these failure modes are visible in a local Docker test with 2 tenants. They only surface at density — which is exactly the configuration you cannot test until you’re in production.
The Failure Mode: Cache Line Eviction and TLB Cascade
The specific bottleneck for naive high-dimensional nearest-neighbour search is LLC (Last Level Cache) thrashing combined with DTLB miss storms.
A modern server CPU (AMD EPYC Genoa, 96 cores) has 384 MB of L3 cache — impressive until you realise a single tenant’s 1M-vector float32 index consumes 5.8 GB. The index doesn’t fit. Every scan evicts the previous tenant’s warm data. The hardware prefetcher, designed for sequential access patterns with stride ≤ 2048 bytes, can’t predict the random access pattern of IVF centroid probing.
The concrete numbers: each LLC miss costs 70–120 ns (DDR5 latency). A flat scan over 1M vectors × 6,144 bytes/vector generates roughly 96,000 cache-line loads (at 64 bytes/line). Even with perfect hardware prefetch, that’s 6.7 ms per query from memory latency alone — 10× worse than your SLA target.
Product Quantization breaks this wall. By encoding each 1536-dim vector into 16 bytes (12:1 compression), a 1M-vector index now fits in 15 MB. That fits in L3. Queries become cache-resident. Distance computation switches from float32 SIMD over 1536 dims to lookup-table operations over 16 bytes. The arithmetic intensity inverts in our favour.
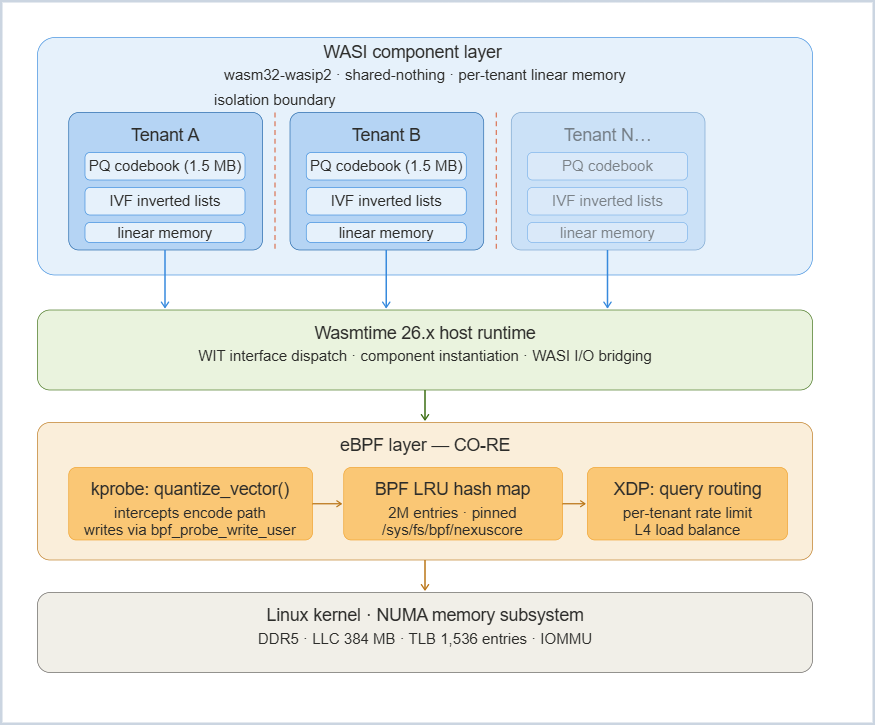
The NexusCore 2026 Architecture
NexusCore implements IVF-PQ (Inverted File Index + Product Quantization) using three cooperating layers: