Day 18: Data Persistence & StatefulSets
Building Bulletproof Data Layers for Production Systems

Today’s Build Agenda
By the end of this lesson, you’ll have deployed:
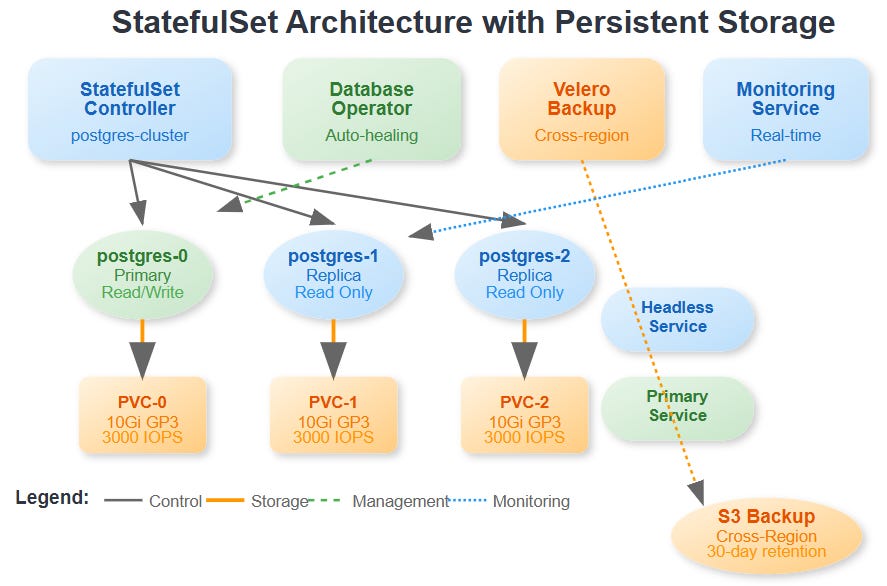
A 3-node PostgreSQL cluster with StatefulSets and persistent volumes
An automated backup system using Velero with cross-region replication
A database operator that handles self-healing and failover
A real-time monitoring dashboard tracking storage metrics
Tested disaster recovery scenarios with actual data corruption
Core Concepts: Why Stateful Workloads Change Everything
StatefulSets vs Deployments
Think of regular Deployments like interchangeable hotel rooms - any pod can handle any request. StatefulSets are like numbered apartments where each resident (pod) has a specific identity and personal storage that follows them around.
When Netflix deploys their recommendation engine’s database cluster, each database node needs its own persistent identity. Node-0 might be the primary writer, Node-1 and Node-2 are read replicas. If Node-1 crashes and comes back, it must resume as Node-1 with its exact same data - not become Node-3 with fresh storage.
Persistent Volumes (PV) vs Persistent Volume Claims (PVC)
PVs are like actual storage drives in a data center. PVCs are like rental contracts that applications use to claim specific storage. Your database pod doesn’t care if it gets an SSD or spinning disk - it just asks for “500GB fast storage” through a PVC.
Database Operators
These are like having a database expert robot that knows how to install, upgrade, backup, and fix your database automatically. Instead of manually SSHing into servers at 3 AM, operators handle the grunt work.