Day 18: Cold Data Lifecycle — Automating Migration to Disk-Based S3

The Abstraction Trap
A junior engineer sees “cold data migration” and reaches for a framework: Kubernetes CronJob, a Python
boto3script, maybe a sidecar container pattern from a blog post dated 2022. They wire ups3cmd, set a 30-day TTL policy in the AWS console, and call it done.Here’s what they missed: they handed control of their I/O scheduler to a garbage-collected runtime running inside a Linux namespace that itself runs inside a hypervisor. Every layer adds latency variance. At 100M+ objects per hour — which is what NexusCore’s multi-tenant hot-to-cold pipeline actually pushes — that variance compounds into missed SLAs, runaway memory usage, and thundering-herd S3
TooManyRequestscascades.The framework hid the actual problem: cold data migration is a kernel I/O problem, not a scheduling problem. The moment you treat it as “just a cron job,” you’ve already lost.
The Failure Mode: TLB Thrash and mmap Pressure
The naive approach spawns one Linux process per tenant for the migration pass. Each process:
Reads a metadata index from disk.
Iterates over candidate objects.
Calls
stat()to get atime/mtime.Calls
sendfile()or re-opens for upload.At scale, this blows up on two fronts:
TLB Pressure: Each process gets its own virtual address space. The kernel’s TLB has to be flushed on every context switch between tenants. With 5,000 active tenants, you’re context-switching thousands of times per second. On a 48-core Xeon, that’s ~400 TLB shootdown IPIs (inter-processor interrupts) per second — each one stalls all cores momentarily. You can observe this directly with
perf stat -e dTLB-load-misses.Scheduler Thrashing: The per-process model produces N blocked I/O tasks competing on the same storage device queue. Linux’s CFS scheduler doesn’t understand “these 5,000 tasks are doing identical disk reads.” It just sees 5,000 runnable processes jockeying for CPU slices, producing constant context-switch overhead measured in microseconds per switch — which at scale translates to whole milliseconds of aggregate stall per batch cycle.
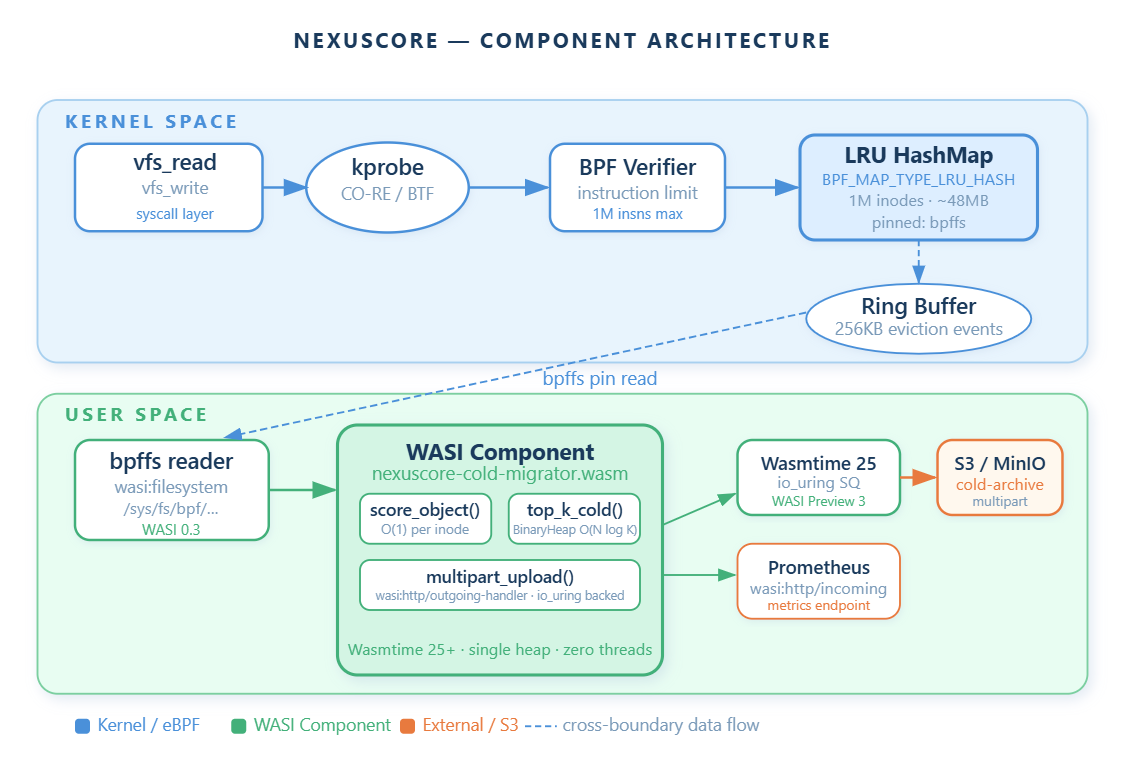
The fix is to collapse all tenant migration logic into a single WASI component with explicit cooperative scheduling, and do the cold/hot tagging in kernel space via eBPF — zero process spawns, zero TLB pressure per tenant.
The NexusCore Architecture: WASI Component + eBPF File Probe
Core Pattern
NexusCore Day 18 implements the following pipeline: