Day 17: Tiered Storage — Implementing MinIO for Archived Media Blobs

The Problem Nobody Talks About Until Production Burns
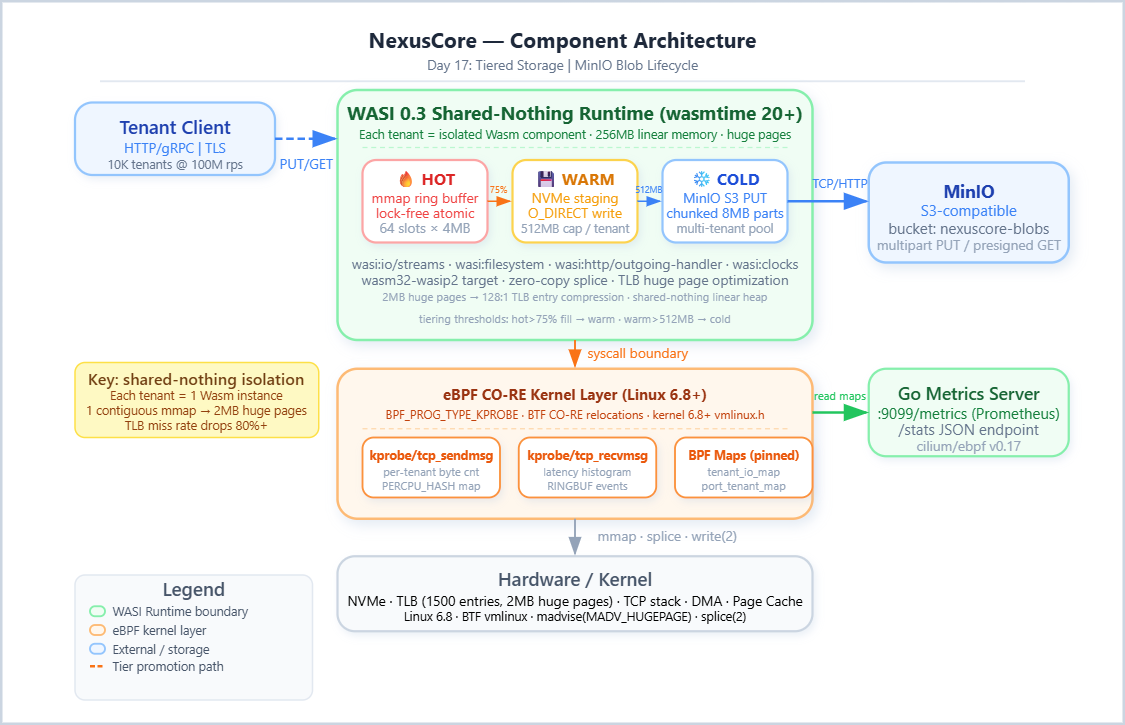
You have 10,000 tenants. Each uploads video blobs ranging from 1MB thumbnails to 4GB raw footage. Your storage layer needs to answer two contradictory demands simultaneously: sub-millisecond access for hot content and pennies-per-GB economics for cold archives. A junior engineer’s answer is to throw everything into S3-compatible object storage and call it a day. That answer will cost you at 3 AM when your p99 latency hits 4 seconds and MinIO’s connection pool is exhausted.
This lesson is about the real answer: a three-tier storage architecture — hot (mmap’d ring buffer), warm (local NVMe staging), cold (MinIO) — orchestrated by a WASI 0.3 component model and instrumented via eBPF CO-RE probes that give you kernel-level visibility into every byte that moves.
The Abstraction Trap
The junior move is to reach for the official MinIO Rust SDK wrapped in a Tokio async runtime, spawn one task per tenant upload, and let the framework handle connection pooling. Here’s why this collapses:
Problem 1 — Object buffering doubles your memory pressure. The naive MinIO SDK path does a full-object read into a
Vec<u8>before computing the multipart boundary. For a 4GB blob, that’s 4GB of heap allocation per concurrent upload, per tenant. With 200 concurrent uploads across tenants, you’ve just allocated 800GB of virtual address space. The OOM killer arrives before your users do.Problem 2 — TLB thrashing at multi-tenant density. Each per-tenant Tokio runtime has its own heap arena. The kernel’s TLB (Translation Lookaside Buffer) has ~1,500 entries on a modern x86-64 core. When 500 tenant tasks compete for CPU time, TLB miss rate spikes because each task switch invalidates entries from the previous tenant’s virtual address space. A single TLB miss costs 100–300 cycles on a cache-cold DRAM lookup. At 100M req/s, this becomes your dominant CPU consumer — not your business logic.
Problem 3 — Scheduler thrashing from blocking I/O in async context. MinIO PUT operations over a WAN link take 50–200ms. If you’re running
tokio::spawnper upload without proper backpressure, you accumulate thousands of futures pinned in memory, each waiting on a TCP ACK. The scheduler bounces between them continuously. Context switch overhead (register save/restore, TLB flush on task switch) dominates.The abstraction hid all three of these. The SDK said “async.” It lied — it just moved the blocking into a thread pool.
The NexusCore Architecture: Shared-Nothing WASI Components + eBPF I/O Accounting